Coursera의 Deep Learning Specialization - Week 5의 강의를 수강하면서 필기한 내용을 바탕으로 정리한 글입니다.
지난 시간에는 Word Embeddings와 NLP(Natural Language Processing) 아이디어 등에 대해 배웠습니다.
이번 시간에는 Sequence to Sequence Models를 살펴 보겠습니다.
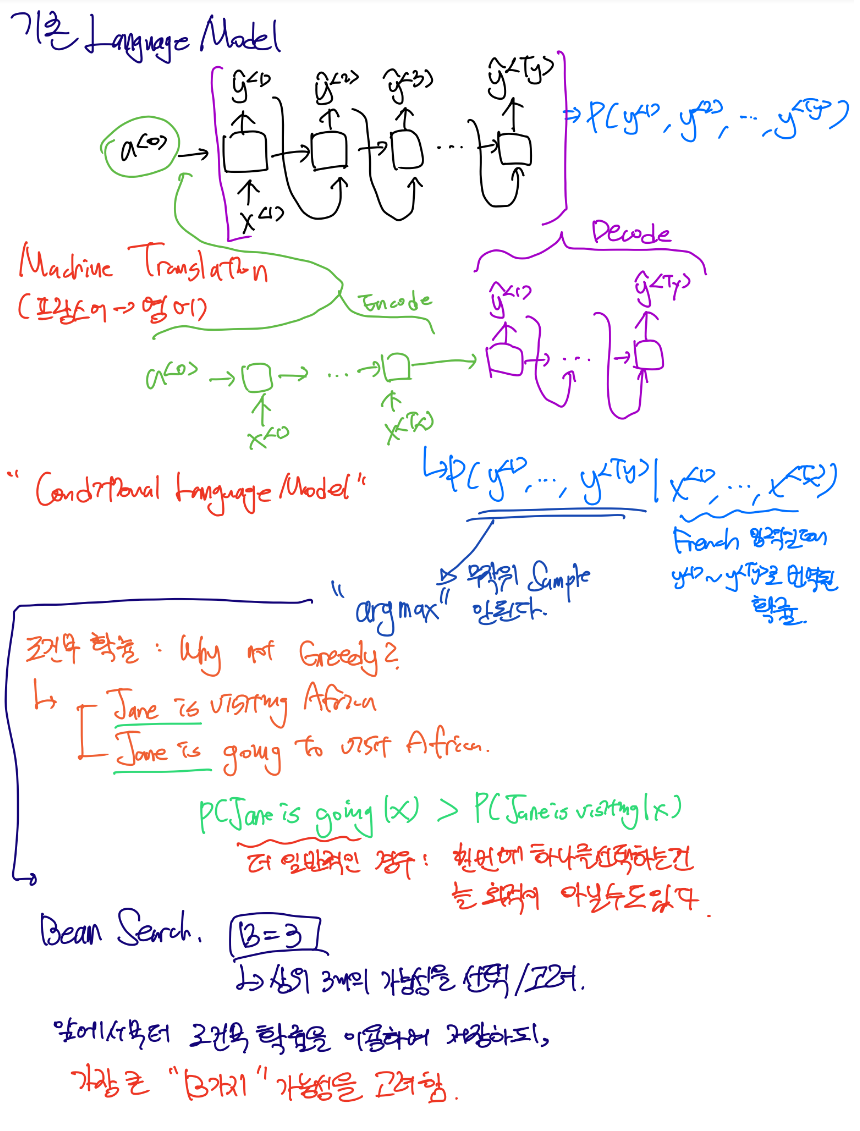
Conditional Language Model
기존의 모델과 다르게, 프랑스어로 구성된 문장이 입력으로 들어오면 영어로 구성된 문장으로 번역하는 모델을 생각해 봅시다. 이 모델은 입력과 출력이 모두 시퀀스로 구성된 Sequence to Sequence 모델의 구성을 띠게 됩니다.
기존 모델에서는 단순한 입력이 바로 신경망에 입력으로 들어갔지만, Machine Translation 모델에서는 입력 하나가 Encode 과정을 거친 뒤 신경망에 들어가, Output으로 나온 데이터가 Decode 과정을 거쳐 출력될 확률을 알려줍니다.
따라서 Machine Translation 모델은 입력 문장에 대한 출력 문장의 확률을 구하는 것과 같기 때문에,
조건부 언어 모델, Conditional Language Model이라고 불립니다.
따라서 입력 문장의 분포를 잘 샘플링하는 것이 정말정말 중요합니다.
무작위 샘플링을 사용하지 않고, argmax를 이용하여 조건부 확률이 가장 높게 번역되는 분포를 찾아야 합니다.
조건부 확률을 최대화하는 알고리즘 중에서, 매 순간 최상의 선택을 찾아가는 Greedy 알고리즘이 있습니다.
하지만 이 방법은 Jane is visiting 과 Jane is going to visit 중에서, 보다 일반적인 선택인 going을 선택하게 되는데 이는 정답이 아닙니다. 이는 언제나 최적의 선택을 하는 것이 번역의 정답이 아니라는 것을 의미합니다.
그래서 Beam Search 알고리즘을 주로 사용합니다.
앞에서부터 조건부 확률을 고려하여 선택할 때, 최상위 "B"가지 선택지를 선택하는 것을 말합니다.
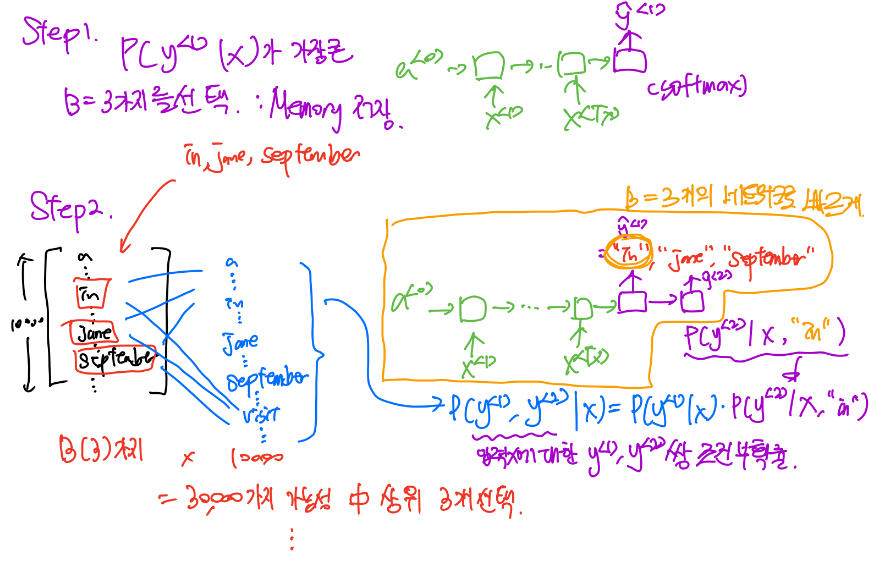
Steps of Beam Search
B는 Beam 변수로, 선택할 가짓수를 의미합니다. B=3이라고 한다면, 최상위 3가지를 선택한다는 의미입니다.
- Step1.
가장 확률이 높은 3가지 단어를 메모리에 저장합니다. - Step2.
다음 위치의 단어를 예측합니다. Step1에서 선택한 B가지 단어를 입력으로 하여, 모든 단어의 가능성을 계산하여 상위 B가지 단어를 선택합니다. - Step3.
Step2에서 선택한 B가지 단어를 입력으로 하여, 모든 단어의 가능성을 계산하여 상위 B가지 단어를 선택합니다. - ...
Beam Search는 Greedy와 다르게, 좀 더 많은 경우의 수를 다루기 때문에 보다 좋은 성능을 보여줍니다.
B=1인 Beam Search 알고리즘은 Greedy 알고리즘과 같습니다.
Refinements to Beam Search : Length Normalization
조건부 확률은 1 이하의 확률값을 입력 시퀀스 길이만큼 곱하게 됩니다. 이는 부동 소수점 연산에 취약한 컴퓨터 연산의 특성상, 결과가 언더플로되어 값이 매우매우 작아집니다. 그리고 모델은 짧은 출력의 번역을 선호하게 됩니다. ( low Ty )
그에 따라, 모든 확률값에 log를 취하도록 합니다. 로그함수는 여전히 증가함수인데다, 감소할 때 보다 안정적인 값을 가지기 때문입니다. 그럼에도 여전히 긴 번역문에 취약하여 짧은 출력을 선호합니다.
따라서, 출력 단어의 수 Ty로 정규화하는 방법을 사용합니다. 이를 Length Normalization이라고 합니다.
또 번역문이 너무 길 경우 값이 매우 작아지는 페널티를 줄이기 위해 Alpha승을 추가하기도 합니다.
B의 최적값은 어떻게 찾을 수 있을까요?
B가 클수록 더 많은 경우를 고려하므로 좋은 결과를 얻지만, 탐색 속도가 그만큼 느려집니다.
반면 B가 작을수록 속도는 빨라지지만, 좋은 결과는 기대할 수 없습니다.
이러한 점을 생각해 보면, Beam Search 알고리즘은 다른 완전탐색 알고리즘인 BFS, DFS보다는 빠르지만 그들처럼 뛰어난 정확성을 보장하지는 않기 때문에 최적의 값을 고려하여 선택하는 것이 중요합니다.

Error Analysis
인간이 번역한 y*에 대한 확률값과 모델이 번역한 y^에 대한 확률값을 함께 계산합니다.
이 두가지 확률값을 비교하여, 어느 값이 더 큰지에 따라 Beam Search 알고리즘과 RNN 모델 중 어느 것이 문제인지를 판단할 수 있습니다.

평가 지표 : Bleu Scores
기계 번역의 성능을 평가하는 지표로 Bleu Scores를 많이 이용합니다.
좋은 번역 결과 Ref1, Ref2가 있고, 기계 번역 모델의 결과 MT가 있습니다.
MT가 Ref1이나 Ref2에 가깝게 번역되었다면, MT가 좋은 성능을 가지고 있다고 판단합니다.
MT 내 단어를 모두 센 뒤, 두 Ref 내 해당 단어가 등장한 횟수를 센 뒤 최댓값을 가져옵니다. 이러한 계산을 Modified Precision이라고 부릅니다.

Bigrams + N-grams
위 Bleu Scores는 순서를 고려하지 않았습니다.
Bigrams는 붙어 있는 2개의 단어쌍을 확인하여, Ref에 얼마나 등장하는지를 카운팅합니다.
나아가 N-grams까지 확장할 수 있습니다. 각 N값에 따라 얻은 결과값은 Pn이 됩니다.
최종 Bleu Scores를 계산하는 방법은, Bleu Penalty인 BP에 각 Pn값을 모두 합친 것을 곱합니다.
페널티는 MT와 Ref의 출력 길이에 따라 다른 값을 이용하는데, 짧은 번역을 선택했을 때 높은 Score를 얻는 것에 대해 페널티를 부여하도록 합니다.

Attention
시퀀스가 길어질수록 성능 평가지표인 Bleu Scores가 감소하는 것을 확인할 수 있습니다.
따라서, 긴 문장에 대해 좋은 성능을 유지하고자 Attention을 사용합니다.
어텐션 모델은 각 단어를 예측할 때, 사람과 유사하게 전체 문장을 다시 확인하여 예측할 단어와 관련 있는 부분만 참고합니다.
인코더에서 양방향 RNN 모델인 BRNN를 이용하여 입력에 대해 양방향의 activation값을 함께 계산합니다.
그리고 모든 activation 값을 참고하여 각 입력 단어들이 예측할 단어에 얼마나 관련있는 지를 의미하는 alpha값을 계산합니다. 이 값들을 모두 더하여, 디코더에서 입력으로 사용되는 C값을 계산합니다.
alpha<m,n>은 m번째 단어가 n번째 단어에 얼마나 주의를 기울여야 하는 지를 수치화한 값입니다.
alpha는 softmax와 같은 방법으로 계산됩니다. 따라서, 각 단어에 대한 alpha의 합(sum(alpha<1,t>))은 1이 됩니다.
s<t-1>과 a<t'>가 Dense Layer에 들어가 e<t,t'> = alpha<t,t'>를 Output으로 가지게 됩니다.
어텐션의 단점은, 비용이 Tx * Ty = 2차(Quadratic)가 되어 연산량이 많다는 점입니다.

Deep Learning Model on Speech Recognition
위에서 배운 Attention Model을 언어 인식에 적용할 수 있습니다.
또는, Connectionist temporal classification(CTC)를 이용합니다.
Output으로 1000개의 문자열이 나오게 되는데, Blank로 구분되지 않는 문자들의 중복을 제거하여 최종 Output을 얻을 수 있습니다. 아래의 경우 "the_q"가 최종 Output입니다.

Trigger Word Detection
Trigger Word Detection이란, 특정 단어를 인식하는 모델을 말합니다. 시리, 에코, 구글 등이 있습니다.
오디오 클립이 입력으로 들어오고, 'Siri'같은 특정 단어가 들어올 때 말한 직후 시점을 '1'로 라벨링하고 이 외의 시점을 '0'으로 라벨링합니다. 하지만 하나의 시점만 '1'로 라벨링하면 0과 1의 균형이 깨져 잘 동작하지 않기 때문에 해당 시점 이후를 '1'로 라벨링할 비율을 임의로 더 늘릴 수 있습니다.

'Deep Learning Specialization' 카테고리의 다른 글
| Transformers [Deep Learning Specialization #15] (0) | 2022.08.23 |
|---|---|
| Word Embeddings [Deep Learning Specialization #13] (0) | 2022.08.18 |
| RNN [Deep Learning Specialization #12] (0) | 2022.08.01 |
| Face Recognition [Deep Learning Specialization #11] (0) | 2022.07.28 |
| Detection [Deep Learning Specialization #10] (0) | 2022.07.27 |




댓글